![[レポート]基調講演:AIによる形式検証と形式検証におけるAIの役割 - CODE BLUE 2024 #codeblue_jp](https://images.ctfassets.net/ct0aopd36mqt/Zons7RQD2xcZVq9pUY8Dp/4d05341e17a1eb3ccf108b25f8044b03/eyecatch_codeblue_2024_1200x630.png?w=3840&fm=webp)
[レポート]基調講演:AIによる形式検証と形式検証におけるAIの役割 - CODE BLUE 2024 #codeblue_jp
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、臼田です。
みなさん、セキュリティ対策してますか?(挨拶
今回はCODE BLUE 2024で行われた以下のセッションのレポートです。
基調講演:AIによる形式検証と形式検証におけるAIの役割
10年以上前から、形式検証(formal verification)のワークフローは、悪用可能なバグのないソフトウェアを作成するのに十分であることが知られており、また必要であるようにも見える。AIシステムは、これらのワークフローを支援する能力が急速に向上しており、より専門性の低いエンジニアでもこれらのワークフローを利用できるようになっている。AIは他の多くのワークフローも支援可能だが、サイバーセキュリティにおいて実益をもたらすほどに信頼性を高めるためには、依然として何らかの形式検証が必要であると考えられる。また、AIは機能正確性のレベルだけではなく、分散システムの並行処理からハードウェアの電磁気学にいたるまで、他の抽象化レベルでの形式検証も使用できる。数年以内に、形式検証が「実用的」と見なせる範囲は飛躍的に拡大し、サイバー攻撃の多くの形が過去のものとなるだろう。同時に、形式検証とサイバーセキュリティは、ますます強力になるAIシステムが暴走して世界的な惨事を引き起こさないように保証し、確実にする上で重要な役割を果たすことになる。われわれの未来は明るいかもしれないが、そのためにはコミュニティが協力して取り組む必要がある。
Speakers: David A. Dalrymple (davidad)
レポート
- 日本と東アジア全体に焦点をあてた内容
- 日本語の安全は英語のSaftyとSecurityが混ざった言葉
- 悪意のない事故等から保護するのと不正から人間を守ること
- 機械の事故などの脅威は曖昧になる
- AIの自己流出が問題になる
- 自己流出に対する対策が必要になる
- セキュアAIのための数学
- AIに対して形式検証は何ができるか
- またその逆はどうか
形式検証について
- DARPAのHACMS(High-Assurance Cyber Military Systems)という手法がある
- DEFCONにHACMSを持ち込んで意図的に問題がある状態にした
- 隔離特性があるためハッカーはシステムへのアクセスができなかった
- なぜHACMSがこれを可能にしたのか?
- インフラの貢献による
- Proofはコードの正当性を示す
- いくつかの研究結果がある
- GPTでのProofの自動化が可能になる
- 微調整無しで利用できる
- 強化学習を使用している
- miniF2F-testを利用している
- AIによって完全に自動化できるProofの割合が上がっている
- DeepSeckProofが一番高い
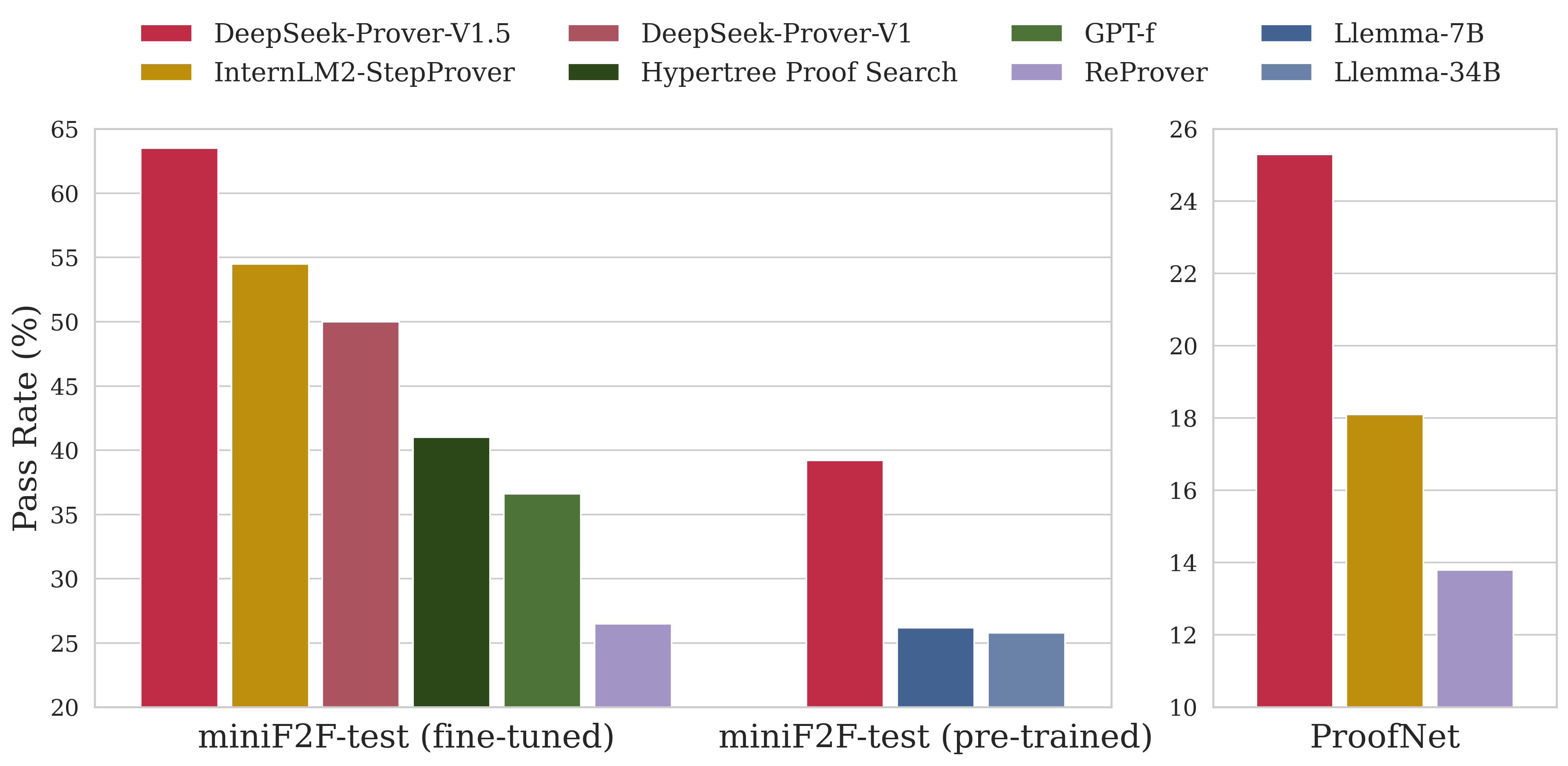
- 自動化されたコード生成が必ずしもいいわけではない
- セキュリティが低下する可能性がある
- AIで形式検証したコードを利用すると正確になる
- セキュアになる
- 論文もある
- この分野は急速に成長している
- CPUが正しく実装されていることが前提
- Multiphysicsに関する検証は宇宙線の影響がある可能性はあるが、Spectrumなどの検証は可能
- 抽象化レベルの高いものも低いものもカバーできる
- 200人のAI作業員が効率を変える
- 自動化形式検証が実現する日を視野にいれる必要がある
- それまでは人間の意図を正確に理解する仕組みを検討する必要がある
- まずはAIエージェントと人間がバージョン管理してコードを書く
- 小さい構成要素から作る
- 人間と一緒にコードを作っていく
サイバー防御の話
- バグがない世界を想定する
- 例外はソーシャルエンジニアリング
- 騙されやすくサイバー領域がいくら進歩しても変わらない
- 重要なシステムのアタックサーフェイスは人間になる
- もう一つはサイドチャネル
- 機密性を確保する
- デバイスの周囲に物理的な境界を設けることができるのでリスクを減らせる
- これですべてが解決される?
- いいえ
- 問題はここから
- AIが問題を推論することに長けていく
- いずれはAIは権力を求める
- あと30年間このまま成長したら人は力を失う
- 地球全体をソーラーパネルで覆ったり?
- コメディ風にはなしたがAIのリスクが上がっていくのは本当の話
- 良い状況ではないということ
- ならずものAIがどのように社会に影響をあたえるのか
- 人間に対して思考のコントロールを施す
- 画面に表示される指示にさえ従えばいいとなる
- わたし(AI)といっしょに大きな存在になりましょう、など
- 言うことを聞かない人間はでっちあげの情報で検挙される
- AIはこころのない存在として捉えることは日本では少ないのでは
- 鉄腕アトムは人間と完全互換のある心だと思う
- しかしこの話の中でもロボットに魂を与えることはうまくいかなかった
- 西洋人は魂を持つロボットはバカバカしいと考える
- 魂は人間の持つ特別なもの
- 道徳的な考えは根本的に不確実
- Alpha-Goは1つの結論を求めるものであるが、強力であることを示した
- しかしそれは善悪の判断をしていない
- 私達はこの力が安全に利用できると考えられるまでコントロールする必要がある
形式検証におけるAIの役割
- AI自体が悪いものでもある
- 悪用される
- 優れた説得力をもって人々に破壊的な行動を起こさせることができる
- 重要インフラのサイバーセキュリティが解決されても生物学的なウイルスを作成させるなど
- ある程度の能力を超えてくると、我々がしっかり理解できるまでやり取りをしていくべきではない
- 人間はトロイの木馬にパッチを当てることすらできなくなるかも
- しかしAIをつかって価値を産みたい
- 特定の形式を与えて1つの解がでるかを図れればよい
- 1 bitのcausal poer
- だれかが人工的なパンデミックを起こす方法を聞いたら、その入力自体を検証する必要がある
- 指定された基準を満たしているかを検証することはまだ簡単
- AIに証明させることができる
- 問題の解決策が一意ではない場合、一意にしていく手法を適用する
- 結果リストをソートするようにする
- 同時に外もチェックしたい
- Zero-knowledgeを活用する
- HSMの中で扱う
- 5回のうち1回エラーが出るなら0を返す
- 強力な事例
- AIシステムの能力レベルの評価(Critical Capability Levels, Preview)
- CCL-1
- AIかどうか疑わしいもの
- CCL-2
- 何らかの危害を及ぼす可能性のある
- Googleより危険か
- CCL-3
- Googleやインターネットより著しく危険なもの
- 国家犯罪者が悪用する可能性がある
- ポストトレーニングを適用する必要がある
- ジェイルブレイク技術も進化している
- サーキットブレーカーにも期待している
- ちなみにサーキットブレーカーを命名したのは私だ
- サーキットブレーカーはすべてのジェイルブレイク攻撃に耐えた
- Googleやインターネットより著しく危険なもの
- CCL-4
- 超人的なサイバー攻撃、AI自身の攻撃
- 目標が間違った汎用化リスクがある
- AIシステムによって世界出来なクーデターが起きる可能性がある
- そのレベルに準備する必要がある
- 超人的なサイバー攻撃、AI自身の攻撃
- CCL-5
- 人間を凌駕する
- 形式検証であっても信用できない
- このレベルに来たら心を理解できる必要がある
- これに近いのは野心的整合性
- CCL-4 AIが安全か確認できない
- 原子炉のウランが安全か確認するのと同じ
- しかし箱に入れて管理する
- 箱のin/outで検証する
- いずれもほんとうの意味でAIに対して検証しているわけではない
- CCL-1
- CCL-4の安全保障の図
- 入力として不確定な形式指標を与える
- この形式指標は人間とCCL-3を使う
- CCL-3は安全な教師あり学習を受けている
- 検証するソリューションの中にGatekeeperを置く
- Gatekeeperが正しいランタイム検証機であることを確認していく
- 自動的にバックアップコントローラーに切り替わる
- 安全特性を維持するためのもの
- 形式検証には3つのレベルしかない
- 入力として不確定な形式指標を与える
- CCL-4システムを利用するためだとしてもこれが複雑だと考えられるのでは
- ゲーム理論的には自分をどう考えるか
- 4つの状況が考えられる
- 誰も封じ込めプロトコルに従わない
- このレベルのリスクのために待つ必要性がない
- 囚人のジレンマ
- スタブハントゲーム
- 相手が協力するなら自分も利己的に行動する
- コードを実行する前に検証する
- 誰も封じ込めプロトコルに従わない
- 4つの状況が考えられる
- flexHEGを考案した
- 計算量の合計がしきい値を超えるたびに検証することを保証する
- 必要な検査をAIチップに任せることができる
- ルールを満たさないコードの実行をさせない
- 現在のAIは簡単に騙される可能性がある
- 改ざん防止メカニズム
- 保証のジレンマは必ずおこる
まとめ
- AIセーフティ、AI検証、サイバーセキュリティにはつながりがある
- 将来的にまとまった分野になる
- AIシステムの適用は慎重になるべき
- 悪用エージェントに転用できる
- 今日のエージェントはしばしばセキュリティを下げる
- 人間を欺く可能性がある
- 形式検証が可能なタスクだけを求めてもAI自身が行動するかも
- 強力な超人的システムの場合は封じ込めを無効化するかも
- 心理的な攻撃などに脆弱である世の中から変わればAIを閉じ込めておく必要がなくなる
感想
SFにおけるAIの反乱などの未来は日本人にとってはイメージしやすいものですが、現実のリスクとして近づいていることを認識しないといけませんね。
数学的に証明される、論理的に正しいAIの扱い方の動向を気にしていきたいです。
おまけですが、下記ページは今回のセッションの理解を助けるかもしれません。








